最近栈长面试了一个 5 年经验的 Java 程序员,简历和个人介绍都提到了精通 Java 多线程,于是我就问了几个多线程方面的问题:
实现多线程有哪几种方式,如何返回结果?- 多个线程如何实现
顺序访问?- 两个线程如何进行
数据交换?- 如何统计 N 个线程的
运行总耗时?- 如何将任务
拆分成多个子任务执行,最后合并结果?
大概问了他这几个问题,答的并不是太好,3、4、5 题都没有真正答上来,其实这几个问题在 JDK 包中都有答案,但他给的是他个人临时思考的方案,而且我个人觉得可能行不通。
工作 5 年了,这几个题都答不好,有点说不过去,我真是醉了。。
实现多线程有哪几种方式,如何返回结果?
继承Thread类
看jdk源码可以发现,Thread类其实是实现了Runnable接口的一个实例,继承Thread类后需要重写run方法并通过start方法启动线程。
继承Thread类耦合性太强了,因为java只能单继承,所以不利于扩展。
实现Runnable接口
通过实现Runnable接口并重写run方法,并把Runnable实例传给Thread对象`,Thread的start方法调用run方法,再通过调用Runnable实例的run方法启动线程。
所以如果一个类继承了另外一个父类,此时要实现多线程就不能通过继承Thread的类实现。
实现Callable接口
通过实现Callable接口并重写call方法,并把Callable实例传给FutureTask对象,再把FutureTask对象传给Thread对象。它与Thread、Runnable最大的不同是Callable能返回一个异步处理的结果Future对象并能抛出异常,而其他两种不能。
结果输出:
Thread1 running... |
多个线程如何实现顺序访问?
join():是线程类 Thread的方法
官方的说明是:Waits for this thread to die.
等待这个线程结束,也就是说当前线程等待这个线程结束后再继续执行,下面来看这个示例就明白了。
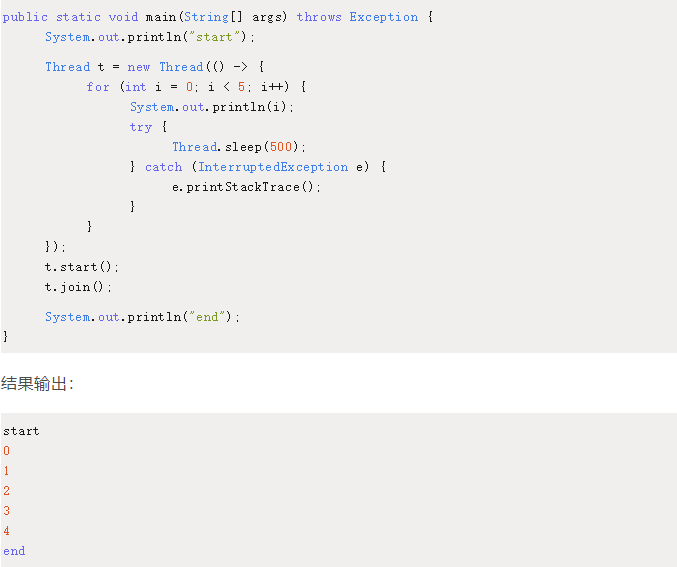
线程t开始后,接着加入t.join()方法,t线程里面程序在主线程end输出之前全部执行完了,说明t.join()阻塞了主线程直到t线程执行完毕。
如果没有t.join(),end可能会在0~5之间输出。
- join()源码:

可以看出它是利用wait方法来实现的,上面的例子当main方法主线程调用线程t的时候,main方法获取到了t的对象锁,而t调用自身wait方法进行阻塞,只要当t结束或者到时间后才会退出,接着唤醒主线程继续执行。millis为主线程等待t线程最长执行多久,0为永久直到t线程执行结束。
两个线程如何进行数据交换?
通过JDK中的 java.util.concurrent.Exchanger类来实现的,并不需要重复造轮子,这个工具类在JDK 1.5中就已经引入了,并不是什么 “新特性”。
- Exchanger 简介
Exchanger 就是线程之间的数据交换器,只能用于两个线程之间的数据交换。Exchanger 提供了两个公开方法:

只带泛型 V(交换的数据对象)的方法,线程一直阻塞,直到其他任意线程和它交换数据,或者被线程中断- 另外一个
带时间的方法,如果超过设置时间还没有线程和它交换数据,就会抛出 TimeoutException 异常;
- Exchanger 实战
简单数据交换
private static void test1() { |
代码逻辑:
- 创建并启动两个线程;
- 进行数据交换前先打印出自己线程的数据;
- 进行数据交换;
- 打印数据交换之后的数据;
输出结果:
Thread-0 AAA |
从结果可以看出,线程 0、1 分别先打印出 A、B,数据交换之后,打印出了 B、A,数据交换正常!
超时数据交换
private static void test2() { |
现在只启动了一个线程,并且设置了超时时间 3 秒。输出结果:

首先线程输出了自己的数据,然后 3 秒后,并没有其他线程和它交换数据,所以抛出了超时异常,最后线程结束运行。
中断数据交换
private static void test3() { |
结果输出:

默认情况下不带超时设置会一直阻塞运行中……,现在我再加入一段中断的逻辑:
private static void test3() throws InterruptedException { |
主线程休眠 3 秒后,中断该线程。输出结果:

输出结果 3 秒后,线程被中断了,抛出了中断异常,线程也停止阻塞,最后线程结束运行。
两两数据交换
另外需要知道是,Exchanger只能用于两个线程之间的数据交换,一个线程开启数据交换之后,会阻塞直到其他任意线程同样开启数据交换达到交换点。
最后来个示例,开启 10 个线程,看它们是怎么两两交换的:
private static void test4() { |
输出结果:
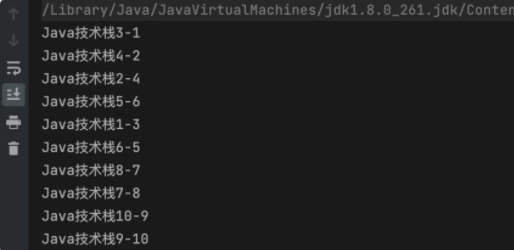
可以看到,10 个线程,都两两交换彼此的数据了。
如何统计 N 个线程的运行总耗时?
CountDownLatch见名思义,即倒计时器,是多线程并发控制中非常有用的工具类,它可以控制线程等待,直到倒计时器归0再继续执行。
给你出个题,控制5个线程执行完后主线徎再往下执行,并统计5个线程的所耗时间。当然可以通过join的形式完成这道题,但如果说统计100个1000个线程呢?难道要写1000个join等待吗?这显然是不现实的。
来做一个例子看看上面的题怎么实现,并理解倒计时器。
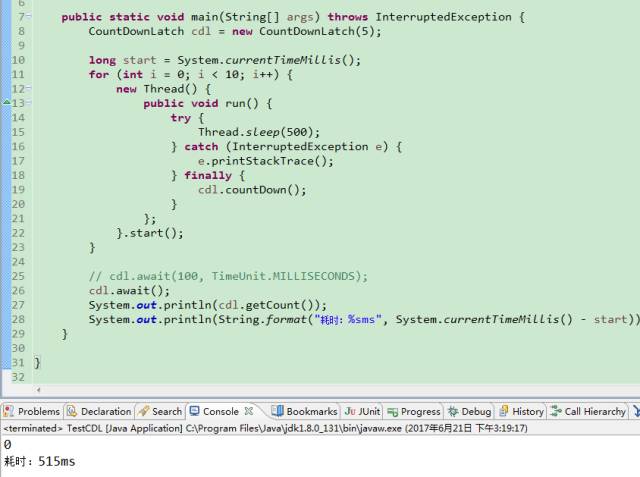
首先通过new CountDownLatch(5)约定了倒计时器的数量,在这里也是线程的数量,每个线程执行完后再对倒计时器-1。countDown()方法即是对倒计时器-1,这个方法需要放在finally中,一定要保证在每个线程中得到释放,不然子线程如果因为某种原因报错倒计时器永远不会清0,则会导报主线程会一直等待。
await()方法即是主线程阻塞等待倒计器归0后再继续往下执行,当然await可以带时间进去,等待多久时间后不管倒计时器有没有归0主线程继续往下执行。
如上面的例子所示,输出了倒计时器最后的数字0,表示倒计时器归0了,也输出了从开始到结束所花费的时间。从这个例子可以完全理解倒计时器的含义,这个工具类在实际开发经常有用到,也很好用。
如何将任务拆分成多个子任务执行,最后合并结果?
Fork/Join是什么?
Fork/Join框架是Java7提供的并行执行任务框架,思想是将大任务分解成小任务,然后小任务又可以继续分解,然后每个小任务分别计算出结果再合并起来,最后将汇总的结果作为大任务结果。其思想和MapReduce的思想非常类似。对于任务的分割,要求各个子任务之间相互独立,能够并行独立地执行任务,互相之间不影响。
Fork/Join的运行流程图如下:
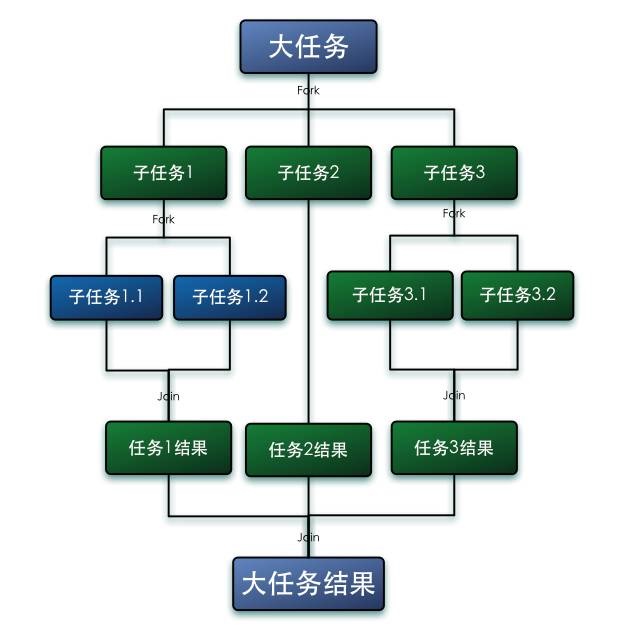
可以通过Fork/Join单词字面上的意思去理解这个框架。Fork是叉子分叉的意思,即将大任务分解成并行的小任务,Join是连接结合的意思,即将所有并行的小任务的执行结果汇总起来。
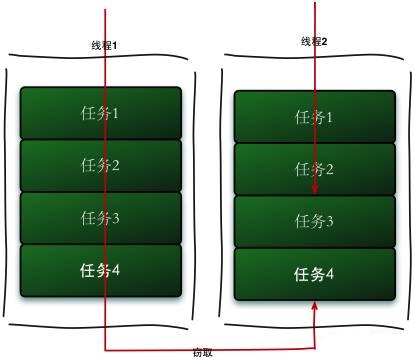
工作窃取算法
ForkJoin采用了工作窃取(work-stealing)算法,若一个工作线程的任务队列为空没有任务执行时,便从其他工作线程中获取任务主动执行。为了实现工作窃取,在工作线程中维护了双端队列,窃取任务线程从队尾获取任务,被窃取任务线程从队头获取任务。这种机制充分利用线程进行并行计算,减少了线程竞争。但是当队列中只存在一个任务了时,两个线程去取反而会造成资源浪费。
工作窃取的运行流程图如下:
Fork/Join核心类
Fork/Join框架主要由子任务、任务调度两部分组成,类层次图如下。
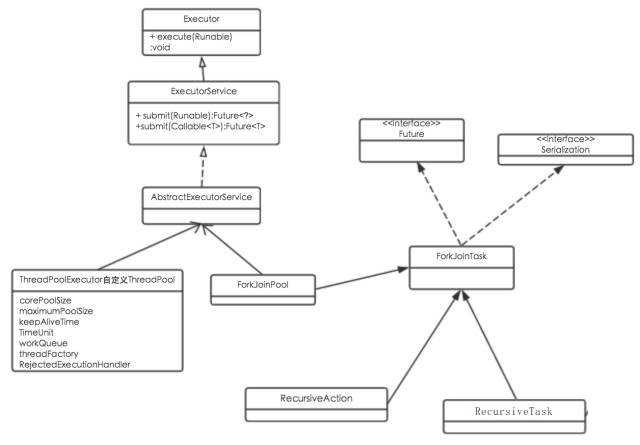
ForkJoinPool
ForkJoinPool是ForkJoin框架中的任务调度器,和ThreadPoolExecutor一样实现了自己的线程池,提供了三种调度子任务的方法:
execute:异步执行指定任务,无返回结果;invoke、invokeAll:异步执行指定任务,等待完成才返回结果;submit:异步执行指定任务,并立即返回一个Future对象;
ForkJoinTask
Fork/Join框架中的实际的执行任务类,有以下两种实现,一般继承这两种实现类即可。
RecursiveAction:用于无结果返回的子任务;RecursiveTask:用于有结果返回的子任务;
Fork/Join框架实战
从1+2+…10亿,每个任务只能处理1000个数相加,超过1000个的自动分解成小任务并行处理;并展示了通过不使用Fork/Join和使用时的时间损耗对比。
import java.util.concurrent.ForkJoinPool; |
这里需要计算结果,所以任务继承的是RecursiveTask类。ForkJoinTask需要实现compute方法,首先需要判断任务是否小于等于阈值1000,如果是就直接执行任务。否则分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会阻塞并等待子任务执行完并得到其结果。
程序输出:
test |
从结果看出,并行的时间损耗明显要少于串行的,这就是并行任务的好处。
尽管如此,在使用Fork/Join时也得注意,不要盲目使用。
- 如果任务拆解的很深,系统内的线程数量堆积,导致系统性能性能严重下降;
- 如果函数的调用栈很深,会导致栈内存溢出;

