常用日志框架
- java.util.logging:是JDK在1.4版本中引入的Java原生日志框架。
- Log4j:Apache的一个开源项目,可以控制日志信息输送的目的地是控制台、文件、GUI组件等,可以控制每一条日志的输出格式,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。虽然已经停止维护了,但目前绝大部分企业都是用的log4j。
- LogBack:是Log4j的一个改良版本。
- Log4j2:Log4j2已经不仅仅是Log4j的一个升级版本了,它从头到尾都被重写了 日志门面slf4j。
日志门面slf4j
上述介绍的是一些日志框架的实现,这里我们需要
用日志门面来解决系统与日志实现框架的耦合性。slf4j,即简单日志门面(Simple Logging Facade for Java),它不是一个真正的日志实现,而是一个抽象层( abstraction layer),它允许你在后台使用任意一个日志实现。
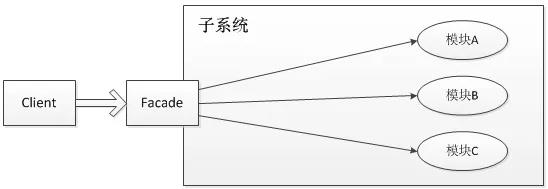
前面介绍的几种日志框架一样,每一种日志框架都有自己单独的API,要使用对应的框架就要使用其对应的API,这就大大的增加应用程序代码对于日志框架的耦合性。
使用了slf4j后,对于应用程序来说,无论底层的日志框架如何变,应用程序不需要修改任意一行代码,就可以直接上线了。
为什么选用log4j2
相比与其他的日志系统,log4j2丢数据这种情况少;disruptor技术,在多线程环境下,性能高于logback等10倍以上;利用jdk1.5并发的特性,减少了死锁的发生;
log4j2的亮点主要体现在:
异步、并发、配置优化、插件机制等
在这列举一下一些网上其他博文中对它们的性能评测: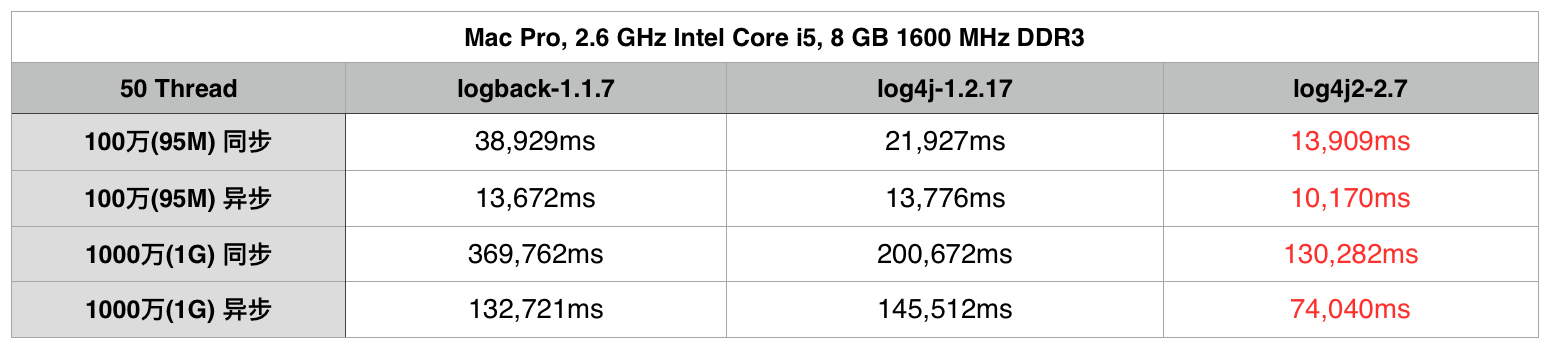
- 可以看到在同步日志模式下, Logback的性能是最糟糕的.
- log4j2的性能无论在同步日志模式还是异步日志模式下都是最佳的.
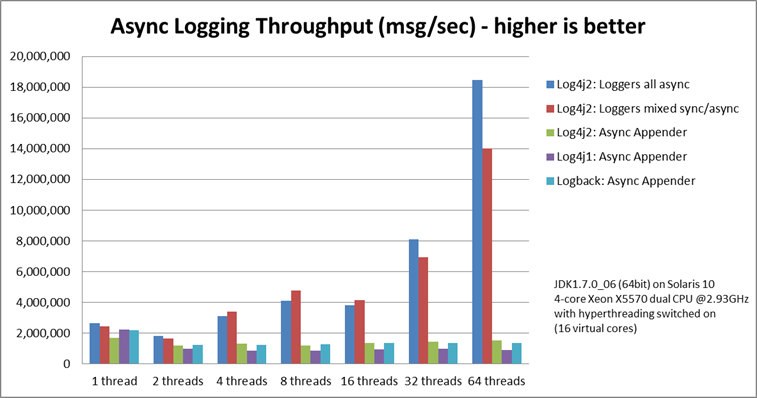
log4j2优越的性能其原因在于log4j2使用了LMAX,一个无锁的线程间通信库代替了,logback和log4j之前的队列,并发性能大大提升。
配置种类
Log4j2的配置可以通过以下四种方式之一来实现:
- 通过 XML、JSON、YAML 或者 properties 格式的配置文件;
- 通过创建一个 ConfigurationFactory 和 Configuration 接口的实现;
- 调用 Configuration接口暴露的方法来在默认配置的基础上添加其他组件;
- 通过在内部 Logger 类上调用方法。
XML基本语法
Log4j2可以使用两种XML格式:
简明和严格。
简明格式可以简化配置,元素名匹配其代表的组件,但不能通过 XML Schema 来验证。
简明格式的元素名和属性名都不是大小写敏感的。另外,属性既可以指定为属性,也可以指定为包含文本值且没有属性的XML元素。以下两段xml是等价的
<!-- 简明 --> |
<!-- 严格 --> |
常用配置
|
文章太长,可参考上述常用配置,各取所需应用到项目中
日志级别
Log4j的级别类org.apache.log4j.Level里面定义了日志级别,日志输出优先级由高到底分别为以下8种。
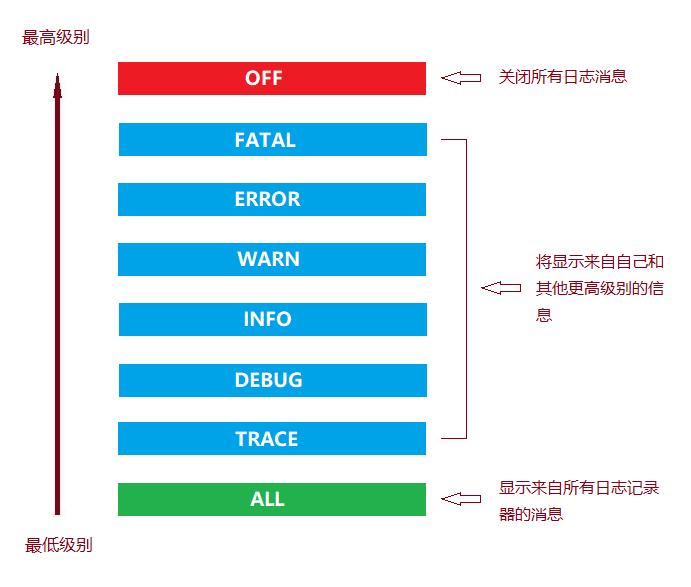
| 日志级别 | 描述 |
|---|---|
| ALL | 所有:所有日志级别,包括定制级别。 |
| TRACE | 跟踪:指明程序运行轨迹,比DEBUG级别的粒度更细。 |
| DEBUG | 调试:指明细致的事件信息,对调试应用最有用。 |
| INFO | 信息:指明描述信息,从粗粒度上描述了应用运行过程。但是不能滥用,避免打印过多的日志。 |
| WARN | 警告:表明会出现潜在错误的情形,有些信息不是错误信息,但是也要给程序员的一些提示。 |
| ERROR | 错误:指出虽然发生错误事件,但仍然不影响系统的继续运行。打印错误和异常信息,如果不想输出太多的日志,可以使用这个级别。 |
| FATAL | 致命:指出每个严重的错误事件将会导致应用程序的退出。这个级别比较高了。重大错误,这种级别可以直接停止程序了。 |
| OFF | 取消:最高等级,关闭所有日志记录。 |
所以,日志优先级别标准顺序:
OFF > FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL |
如果将log level设置在某一个级别上,那么比此级别优先级高的log都能打印出来。如,如果设置优先级为WARN,那么OFF、FATAL、ERROR、WARN 4个级别的log能正常输出,而INFO、DEBUG、TRACE、ALL级别的log则会被忽略。
Log4j建议使用四个级别,优先级从高到低分别是:
ERROR、WARN、INFO、DEBUG
Configuration元素
| 属性名 | 功能 |
|---|---|
| advertiser | 将用于通知单独的FileAppender或SocketAppender配置的Advertiser插件名称。提供的唯一的Advertiser插件是“multicastdns”。 |
| dest | err将输出到stderr,或文件路径或URL。 |
| monitorInterval | 检查更改文件配置之前经过的最短时间(以秒为单位) |
| name | 配置的名称 |
| packages | 逗号分隔的包名称列表用来搜索插件。每个类加载器只加载一次插件,所以更改此值可能不会对重新配置产生任何影响。 |
| schema | 标识类加载器定位用于验证配置的XML模式的位置。仅当strict设置为true时有效。如果未设置,则不会执行模式验证。 |
| shutdownHook | 指定当JVM关闭时Log4j是否应自动关闭。关闭挂钩默认启用,但可以通过将此属性设置为“disable”来禁用 |
| shutdownTimeout | 设置当JVM关闭后Appender和后台任务超时多少毫秒才关闭。默认为 0 ,表示每个Appender使用其默认的超时,不等待后台任务。这仅是个提示,而不能保证关闭进程不会花费更长的时间。将此值设置得太低会增加未写入最终目的地的未完成日志事件的风险。如果shutdownHook属性未设置,那么将不会使用该属性 |
| status | 应该记录到控制台的内部Log4j事件的级别。此属性的有效值为“trace”,“debug”,“info”,“warn”,“error”和“fatal”。Log4j将向状态记录器记录有关初始化,翻转和其他内部操作的详细信息。如果您需要对log4j进行故障排除,则设置status=”trace”是你可用的第一个工具之一。 |
| strict | 使用严格的 XML 格式, JSON格式的配置文件不支持该属性 |
| verbose | 加载插件时是否显示诊断信息 |
注:如果应用运行在Weblogic上时,修改项目中的配置文件不会自动加载生效(
monitorInterval属性失效),必须重启加载应用才可以,考虑到不能随便停止应用的需求,可以通过编程方法来进行配置log4j,从数据库中动态读取配置信息。
Appender元素
Log4j使用Appender将日志事件数据写到各种目标位置(目前可以为控制台、文件、多种数据库 API、远程套接字服务器、Apache Flume、JMS、远程 UNIX Syslog daemon)。
每个Appender都必须要有一个name属性,用来区别其他Appender的唯一标识,该标识的值在Logger中通过AppenderRef来引用,从而将该Appender配置到该 Logger 中。下面介绍常用的Appender。
ConsoleAppender
| 参数名 | 类型 | 描述 |
|---|---|---|
| filter | Filter | 指定一个过滤器来决定是否将日志事件传递给 Appender 处理。可以指定为一个 CompositeFilter 来使用多个过滤器。 |
| layout | Layout | 指定格式化 LogEvent 的 Layout。如果没有指定 Layout,则默认使用 %m%n 格式。 |
| follow | boolean | 在配置好之后,是否可以通过System.setOut 或 System.setErr来重新指定输出位置为 System.out 或 System.err。不能在 Windows下用于Jansi,也不能和 direct 属性一起使用 |
| direct | boolean | 绕开 java.lang.System.out/.err 直接写入 java.io.FileDescriptor。当输出重定向到文件或其他目标时可以节约10倍的性能消耗。不能在 Windows 下用于Jansi,也不能和follow属性一起使用。在多线程应用中,输出不会遵循 java.lang.System.setOut()/.setErr(),而是可能会和其他输出纠缠在一起输出到java.lang.System.out/.err。该属性是2.6.2版本新增的,目前仅在Linux和Windows下的OracleJVM环境中测试过 |
| name | String | (必选) Appender 的名称,表示区别于其他 Appender 的唯一标识。 |
| ignoreExceptions | boolean | 默认为true,表示当输出事件时出现的异常将会被内部记录而忽略。当设置为false时,则会将异常传播给调用者。当将该 Appender 包装成 FailoverAppender 时,必须设置为 false。 |
| target | String | SYSTEM_OUT 或 SYSTEM_ERR。默认为 SYSTEM_OUT。 |
RollingFileAppender
| 参数名 | 类型 | 描述 |
|---|---|---|
| append | boolean | 当为true(默认)时,日志记录将会添加到文件末尾。设置为 false 时,日志记录写入文件之前会清空文件。 |
| bufferedIO | boolean | 当为true(默认)时,日志记录将会写入一个缓冲区,当缓冲区满或设置了 immediateFlush,日志记录才会写入磁盘中。该属性不能使用文件锁。缓冲 I/O 能够显著提高性能,即使启用了immediateFlush |
| immediateFlush | boolean | 当为true(默认)时,每次写入都会跟随一次 flush 。这将保证数据写入磁盘,但会影响性能。仅当使用异步 Logger 的 Appender 时设置每次写入都进行 flush 才有用。异步的 Logger 和 Appender 会在一批次的日志事件末尾自动flush,即使该属性设置为false,这种方式也可以保证数据写入磁盘,但是更有效率 |
| bufferSize | int | 当bufferedIO为true时,该属性用来设置缓冲区的大小,默认为 8192字节 |
| createOnDemand | boolean | Appender是按需(on-demand)创建文件的。仅当日志事件通过所有过滤器并到达 Appender 时,该 Appender 才会创建文件。默认为 false |
| filter | Filter | 指定一个过滤器来决定是否将日志事件传递给 Appender 处理。可以指定为一个 CompositeFilter 来使用多个过滤器。 |
| fileName | String | 设置写入日志记录的文件名。如果该文件或其父目录不存在,则会自动创建 |
| filePattern | String | 归档日志文件的文件名模式(pattern)。该模式依赖于所用的RolloverPolicy 。DefaultRolloverPolicy可以接受兼容SimpleDateFormat的日期/时间或表示一个整数的计数器的 %i 。该模式也支持运行时插入值(interpolation),故任何 Lookup(比如 DateLookup)都可以包含该模式。 |
| layout | Layout | 指定格式化 LogEvent 的 Layout 。如果没有指定 Layout ,则默认使用 %m%n 格式 |
| name | String | (必选) Appender 的名称,表示区别于其他 Appender 的唯一标识 |
| policy | TriggeringPolicy | 设置确定是否创建文件的规则(policy) |
| strategy | RolloverStrategy | 设置确定归档文件的文件名和位置的策略(strategy) |
| ignoreExceptions | boolean | 默认为true,表示当输出事件时出现的异常将会被内部记录而忽略。 当设置为 false 时,则会将异常传播给调用者。当将该 Appender 包装成 FailoverAppender 时,必须设置为 false |
| filePermissions | String | 设置每当创建文件时所用的 POSIX 格式的文件属性权限。底层文件系统应该支持POSIX格式的文件属性视图。比如: rw——- 或 rw-rw-rw- 等 |
| fileOwner | String | 指定每次创建文件的属主。由于权限原因,可能不允许更改文件属主,这时会抛出IOException。仅当有效的目标用户ID和文件的用户 ID 相同,或目标用户ID具有修改文件属主的权限(如果_POSIX_CHOWN_RESTRICTED 在日志文件路径下有效)时才会处理。底层文件系统应该支持owner文件属性视图。 |
| fileGroup | String | 指定每次创建文件的属组。底层文件系统应该支持POSIX格式的文件属性视图。 |
注:RollingFileAppender 不支持文件锁。
触发规则
CompositeTriggeringPolicy组合了多个触发规则(policy),如果配置的任意规则返回true时,则CompositeTriggeringPolicy也返回true,也发生了触发。 CompositeTriggeringPolicy通过将其规则包装进 Policies 元素即可配置。
下例的日志滚动规则:当JVM启动时、日志文件大小达到20MB且当前日期不再匹配日志开始日期时就滚动日志。
<Policies> |
OnStartupTriggeringPolicy
OnStartupTriggeringPolicy:在日志文件比当前JVM启动时间较早时进行日志滚动,同时遵循下面的minSize属性规则。
| 属性名 | 类型 | 描述 |
|---|---|---|
| minSize | long | 日志文件滚动的最小大小。值为0表示不管文件大小为多大都滚动。默认值 1 将阻止对空文件进行滚动。 |
TimeBasedTriggeringPolicy
TimeBasedTriggeringPolicy:只要日期/时间模式(pattern)不再应用于当前文件时就进行日志滚动。这种规则通过 interval 和 modulate 属性来配置。
| 属性名 | 类型 | 描述 |
|---|---|---|
| interval | integer | 基于日期/时间模式中的最小的时间单位多久滚动一次。如filePattern参数中使用小时作为最小的时间单位时(/appData/logs/myApp/$${date:yyyy-MM-dd}/myApp-%d{yyyy-MM-dd HH}-%i.log),该参数值为4,则表示每 4 小时滚动一次。默认值为 1 。 |
| modulate | boolean | 是否调整interval属性值,以便下次滚动发生在interval边界处。如果时间单位为小时,当前时间为早上3点,间隔为4小时,则第一次滚动将发生在早上 4 点时(而不是早上 7点),后续滚动将发生在 早上 8 点、中午 12 点、下午 4 点等时刻。 |
| maxRandomDelay | integer | 滚动操作随机延迟的最长秒数。默认0表示无延迟。该设置在有多个应用同时滚动日志的服务器上很有用,可以扩宽滚动日志的的负载时间范围,避免某一个时刻由于滚动日志造成高 I/O 压力 |
<!-- 同时指定了基于时间和大小的触发规则,一天最多创建7个归档文件(多于7个时删除时间最早的归档文件), |
SizeBasedTriggeringPolicy
SizeBasedTriggeringPolicy:在文件大小达到指定的大小时进行日志滚动。文件大小可以使用 KB 、MB 或 GB 等后缀。
<!-- 同时指定了基于时间和大小的触发规则,一天最多创建7个归档文件(未配置DefaultRolloverStrategy时, |
CronTriggeringPolicy
CronTriggeringPolicy:基于cron表达式来滚动日志。
| 属性名 | 类型 | 描述 |
|---|---|---|
| schedule | String | 和Quartz调度器一样的cron表达式 |
| evaluateOnStartup | boolean | 在启动时,该cron表达式将基于文件的上次修改时间戳来求值。 |
<!-- 基于cron表达式和大小的触发规则,直接将日志以编号无限制的方式写入归档文件中。 |
滚动策略
DirectWriteRolloverStrategy
DirectWriteRolloverStrategy:将日志事件直接写入filePattern参数值表示的文件。该策略不进行文件重命名。如果基于大小的触发规则要在特定时间段内写入多个文件,这些文件编号将从1开始持续递增,直到出现基于时间的滚动。
注:
如果filePattern参数值中有一个表示压缩格式的后缀以进行文件压缩,当应用关闭时当前文件并不会进行压缩。此外,如果由于时间改变造成filePattern不在匹配当前文件了,那么当前文件在下次启动时也不会进行压缩。
<!-- 限制每小时里文件编号最大为 10 --> |
| 属性名 | 类型 | 描述 |
|---|---|---|
| maxFiles | String | 匹配filePattern期间所允许的最大文件数。如果文件数超过了该属性值,则最早文件编号的文件将会删除。如果指定了该属性值,那么必须要大于 1。如果该属性值小于0或省略掉了,则将不会再限制文件编号。 |
| compressionLevel | Integer | 设置压缩级别0 - 9。0 = none,1 = best speed,9 = best compression。仅应用于 ZIP 文件。 |
| tempCompressedFilePattern | String | 压缩时归档文件的文件名模式。 |
DefaultRolloverStrategy
DefaultRolloverStrategy:可同时接受RollingFileAppender中filePattern属性值中日期/时间和整数计数器(%i)的匹配模式
- 当日期/时间满足条件时,则会
使用当前的日期/时间生成新的日志文件- 如果filePattern属性值中含有一个
整数计数器 %i,则在每次滚动时该整数都会增加- 如果filePattern属性值中同时
包含了日期/时间和整数计数器(%i),计数器会在日期/时间不变时,而满足其他滚动触发条件时(文件大小)开始自增,直到日期/时间发生变化时,计数器会重新自增- 以.gz、.zip、.bz2、deflate、pack200或xz结尾的filePattern值,会在日志文件归档时,以后缀对应的格式进行压缩
<!-- 保留 20 个文件的重新生成策略(多于设定值时删除时间最早的归档文件),未配置DefaultRolloverStrategy时, |
| 参数名 | 类型 | 描述 |
|---|---|---|
| fileIndex | String | 如果设置为max(默认),则具有更大索引的文件比具有更小索引的文件内容更新。如果设置为min,文件将重命名。设置nomax,则min和max属性值都将会被忽略,文件编号每次滚动都会递增1,无限制 |
| min | Integer | 计数器的最小值,默认为 1。 |
| max | Integer | 计数器的最大值。一旦计数器达到了最大值,最早的归档将会在每次滚动时被删除。默认值为 7。 |
| compressionLevel | Integer | 设置压缩级别0 - 9。0 = none,1 = best speed(最快压缩),9 = best compression(最好压缩)。仅应用于ZIP文件。 |
| tempCompressedFilePattern | String | 压缩时归档文件的文件名模式。 |
默认的滚动策略支持三种递增计数器
- fileIndex 属性min设置为1,max设置为3,文件名为foo.log,文件名模式为foo-
%i.log。(向下重命名)

- fileIndex 属性设置为max,而所有其他设置和上面都一样。
(向上重命名)
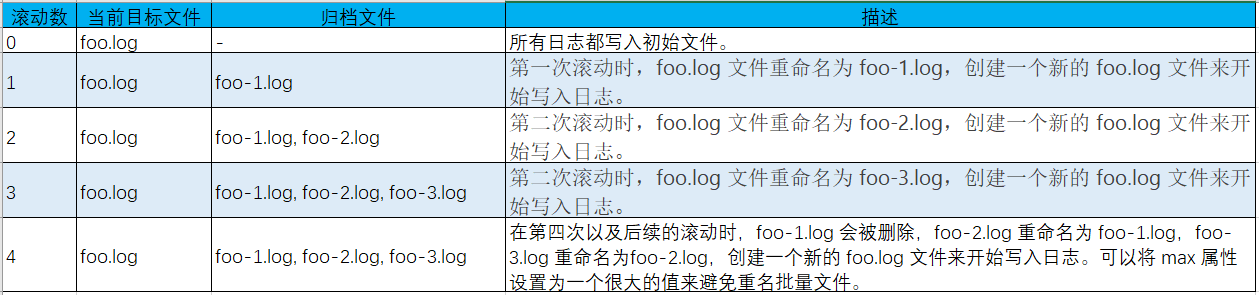
上面两种方式都有可能导致批量重命名日志文件,所以
自2.8版本开始,fileIndex 参数添加了nomax属性。
Delete(归档保留规则)
Log4j 2.5 引入了删除动作(Delete action)。在滚动删除旧的日志文件时,相比使用DefaultRolloverStrategy 的 max 属性,该功能可以让用户拥有更多的删除控制。删除动作可以让用户配置若干个条件来删除相对于基准目录的文件。
注:该功能可以删除非日志文件,使用时一定要小心。可以通过 testMode 属性来测试配置是否会错删文件。
| 属性名 | 类型 | 描述 |
|---|---|---|
| basePath | String | (必选)指定扫描要删除文件的基准目录。 |
| maxDepth | int | 指定扫描的目录的最大层级。0值表示仅能访问基准目录(安全限制不能访问的情况除外)。Integer.MAX_VALUE值表示可以访问所有层级。默认值为1,表示仅扫描基准目录下的文件。 |
| followLinks | boolean | 设置是否跟随符号链接。默认为 false |
| testMode | boolean | 如果设置为true,文件不会实际删除,而是在status logger打印一条INFO级别的消息。可以使用该功能来测试是否会错删文件。默认为 false。 |
| pathSorter | PathSorter | 设置一个实现了PathSorter接口的插件来在选择删除文件之前排列文件。默认优先排列最近改动的文件。 |
| pathConditions | PathCondition | 如果没有指定 ScriptCondition 则必须指定一个或多个PathCondition元素。如果指定了不止一个条件,则这些条件都需要在删除之前接受某个路径(IfFileName)。这些条件可以嵌套,只有外部条件接受某个路径之后,其内部条件才会决定是否接受该路径。如果这些条件没有嵌套,则它们的执行顺序是任意的。这些条件也可以 通过使用IfAll,IfAny和IfNot等组合条件进行AND、OR和NOT等逻辑运算。用户也可以创建自定义条件或使用内置条件: IfFileName:接受匹配正则表达式或glob的文件路径,IfLastModified:接受比指定时段早或一样早的文件,IfAccumulatedFileCount:在遍历文件树时文件总数超过文件数上限后接受路径,IfAccumulatedFileSize:在遍历文件树时文件总大小超过上限后接受路径,IfAll:如果所有内嵌条件都接受了某个路径才会接受该路径,相当于AND逻辑。内嵌条件的执行顺序是任意的,IfAny:如果任意一个内嵌条件接受了某个目录就接受该目录,相当于OR逻辑。内嵌条件的执行顺序是任意的,IfNot:如果内嵌条件不接受某个路径就接收该路径,相当于 NOT 逻辑。 |
| scriptCondition | ScriptCondition | 如果没有指定PathConditions则必须指定该属性。ScriptCondition元素应该通过包含Script,ScriptRef或ScriptFile元素来指定一个脚本。这里不做重点介绍。 |
- IfFileName 条件属性:
| 属性名 | 类型 | 描述 |
|---|---|---|
| glob | String | 如果regex属性没有指定则必须指定该属性。使用受限的模式语言(类似于正则表达式但语法更简单)来匹配相对路径(基于基准路径)。 |
| regex | String | 如果glob属性没有指定则必须指定该属性。使用Pattern类定义的正则表达式来匹配相对路径(基于基准路径)。 |
| nestedConditions | PathCondition[] | 可选的内嵌 PathCondition 结合。 |
注:glob和regex属性必须二选一
- IfLastModified 条件属性:
| 属性名 | 类型 | 描述 |
|---|---|---|
| age | String | (必须)指定一个时段。该条件接受比指定时段早或一样的文件。s(秒)、m(分)、h(时)、d(天) |
| nestedConditions | PathCondition[] | 可选的内嵌 PathCondition 结合。 |
<!-- 使用cron触发规则,每天零时零分零秒触发一次。归档文件存放在当前年月目录。所有位于基准目录下 |
- IfAccumulatedFileCount 条件属性:
| 属性名 | 类型 | 描述 |
|---|---|---|
| exceeds | int | (必须)指定一个文件总数上限值。如果文件数超过了该上限值则删除文件 |
| nestedConditions | PathCondition[] | 可选的内嵌 PathCondition 结合。 |
- IfAccumulatedFileSize 条件属性:
| 属性名 | 类型 | 描述 |
|---|---|---|
| exceeds | int | (必须)指定一个文件总大小上限值。如果文件累计总大小超过了该上限值则删除文件。该值可以通过 KB、MB 或 GB 等后缀来指定,例如 50GB。 |
| nestedConditions | PathCondition[] | 可选的内嵌 PathCondition 结合。 |
<!-- 使用基于时间和文件大小的触发规则,每天最多生成100个归档日志文件,使用gzip压缩,存放在当前年月目录, |
PosixViewAttribute(归档自定义文件属性)
Log4j 2.9 引入了一个PosixViewAttribute动作,用户可以更好地控制选择文件的属主、属组、权限等属性中的哪一个来作为滚动依据。PosixViewAttribute动作让用户配置一个或多个条件来筛选相对于基准目录的文件。
| 属性名 | 类型 | 描述 |
|---|---|---|
| basePath | String | (必选)的用于扫描文件的基本目录。 |
| maxDepth | int | 指定扫描的目录的最大层级。0值表示仅能访问基准目录(安全限制不能访问的情况除外)。Integer.MAX_VALUE 值表示可以访问所有层级。默认值为1,表示仅扫描基准目录下的文件。 |
| followLinks | boolean | 设置是否跟随符号链接。默认为 false。 |
| pathConditions | PathCondition[] | 参考DeletePathCondition。 |
| filePermissions | String | 设置每当创建文件时所用的 POSIX 格式的文件属性权限。底层文件系统应该支持POSIX格式的文件属性视图。如: rw——- 或 rw-rw-rw- 等。 |
| fileOwner | String | 指定每次创建文件的属主。由于权限原因,可能不允许更改文件属主,这时会抛出 IOException 。仅当有效的目标用户 ID 和文件的用户 ID 相同,或目标用户 ID 具有修改文件属主的权限(如果 _POSIX_CHOWN_RESTRICTED在日志文件路径下有效)时才会处理。底层文件系统应该支持 owner 文件属性视图。 |
| fileGroup | String | 指定每次创建文件的属组。底层文件系统应该支持POSIX格式的文件属性视图。 |
<!-- 为当前和已滚动日志文件定义了不同的 POSIX 文件属性视图 --> |
RollingRandomAccessFileAppender
RollingRandomAccessFileAppender基本上与RollingFileAppender相同,只是RollingRandomAccessFileAppender的缓冲是不可关闭的,它使用ByteBuffer + RandomAccessFile来代替BufferedOutputStream。实际测试表明,使用 RollingRandomAccessFileAppender 比使用设置了 bufferedIO=true 的RollingFileAppender 有提高 20-200% 的性能提升。
JDBCAppender
JDBCAppender 可以使用标准的JDBC将日志事件写入关系型数据库表中。
- 可以通过使用JNDI数据源或自定义的工厂方法(都支持数据库连接池)来获取 JDBC 连接。
- 如果配置的 JDBC 驱动支持批处理语句(batch statement),且bufferSize设置为一个正数,日志事件就可以分批处理。
从 Log4j 2.8 开始,有两种配置日志事件的数据列映射:
- 仅允许字符串和时间戳的原始
ColumnConfig风格- 使用Log4j内置的类型转换(支持更多数据类型)的新的
ColumnMapping 插件
操作实例
web.xml 配置
log4j2.xml这个名字是默认的,放在resource目录下的,如果你是采用默认的,那么web.xml里就不需要配置。如果需要自定义路径记得在web.xml里如下配置<context-param>
<param-name>log4j2ConfigLocation</param-name>
<param-value>classpath:config/log4j2.xml</param-value>
</context-param>SpringBoot 配置
如果自定义了文件名,需要在application.yml中配置logging:
config: xxxx.xml
level:
cn.jay.repository: trace默认名
log4j2-spring.xml放在resource目录下,就省下了在application.yml中配置log4j2配置内容
<!-- 配置了两个输出方式,Console和JDBC也就是控制台和数据库,其中com.amayadream.webchat.listener.
PoolManager是一个连接池管理类,getConnection方法是获取Connection对象,代码会在下面贴出.
数据库名为syslog,一共六个字段分别为id,class,function,message,leavl,time,类型都是varchar2,id为
主键,默认值为sys_guid()
tableName是数据库中日志表的表名,Column是数据库的字段,pattern是字段的值,因为我用的是oracle数据库,id
用的是sys_guid(),所以在这里省略以实现不重复的主键效果 -->
<Configuration status="INFO" monitorInterval="1800">
<appenders>
<Console name="consolePrint" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss} [%t] %-5level %logger{36} - %msg%n" />
</Console>
<JDBC name="databaseAppender" tableName="SYSLOG">
<ConnectionFactory class="com.amayadream.webchat.listener.PoolManager" method="getConnection" />
<!--<Column name="ID" pattern=""/>-->
<Column name="CLASS" pattern="%C" />
<Column name="FUNCTION" pattern="%M" />
<Column name="MESSAGE" pattern="%m" />
<Column name="LEAVL" pattern="%level" />
<Column name="TIME" pattern="%d{yyyy-MM-dd HH:mm:ss.SSS}" />
</JDBC>
</appenders>
<loggers>
<root level="info">
<appender-ref ref="consolePrint" />
<AppenderRef ref="databaseAppender" level="INFO" />
</root>
</loggers>
</Configuration>Connection获取
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
import org.apache.commons.dbcp.ConnectionFactory;
import org.apache.commons.dbcp.DriverManagerConnectionFactory;
import org.apache.commons.dbcp.PoolableConnectionFactory;
import org.apache.commons.dbcp.PoolingDriver;
import org.apache.commons.pool.ObjectPool;
import org.apache.commons.pool.impl.GenericObjectPool;
import org.junit.Test;
public class PoolManager {
private static String driver = "oracle.jdbc.driver.OracleDriver";
private static String url = "jdbc:oracle:thin:@localhost:1521:SYSLOG";
private static String Name = "*****";
private static String Password = "*****";
private static Class driverClass = null;
private static ObjectPool connectionPool = null;
public PoolManager() {
}
/**
* 装配配置文件
*/
private static void loadProperties(){
try {
InputStream stream = PoolManager.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties props = new Properties();
props.load(stream);
driver = props.getProperty("driver");
url = props.getProperty("url");
Name = props.getProperty("username");
Password = props.getProperty("password");
} catch (FileNotFoundException e) {
System.out.println("读取配置文件异常");
} catch(IOException ie){
System.out.println("读取配置文件时IO异常");
}
}
/**
* 初始化数据源
*/
private static synchronized void initDataSource(){
if (driverClass == null) {
try{
driverClass = Class.forName(driver);
}catch (ClassNotFoundException e){
e.printStackTrace();
}
}
}
/**
* 连接池启动
*/
public static void startPool(){
loadProperties();
initDataSource();
if (connectionPool != null) {
destroyPool();
}
try {
connectionPool = new GenericObjectPool(null);
ConnectionFactory connectionFactory = new DriverManagerConnectionFactory(url, Name, Password);
PoolableConnectionFactory poolableConnectionFactory = new PoolableConnectionFactory(connectionFactory, connectionPool, null, null, false, true);
Class.forName("org.apache.commons.dbcp.PoolingDriver");
PoolingDriver driver = (PoolingDriver) DriverManager.getDriver("jdbc:apache:commons:dbcp:");
driver.registerPool("dbpool", connectionPool);
System.out.println("装配连接池OK");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void destroyPool(){
try {
PoolingDriver driver = (PoolingDriver) DriverManager.getDriver("jdbc:apache:commons:dbcp:");
driver.closePool("dbpool");
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 取得连接池中的连接
* @return
*/
public static Connection getConnection() {
Connection conn = null;
if(connectionPool == null)
startPool();
try {
conn = DriverManager.getConnection("jdbc:apache:commons:dbcp:dbpool");
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
/**
* 获取连接
* getConnection
* @param name
* @return
*/
public static Connection getConnection(String name){
return getConnection();
}
/**
* 释放连接
* freeConnection
* @param conn
*/
public static void freeConnection(Connection conn){
if(conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 释放连接
* freeConnection
* @param name
* @param con
*/
public static void freeConnection (String name,Connection con){
freeConnection(con);
}
public void test(){
try {
Connection conn = PoolManager.getConnection();
if(conn != null){
Statement statement = conn.createStatement();
ResultSet rs = statement.executeQuery("select * from syslog");
int c = rs.getMetaData().getColumnCount();
while(rs.next()){
System.out.println();
for(int i=1;i<=c;i++){
System.out.print(rs.getObject(i));
}
}
rs.close();
}
PoolManager.freeConnection(conn);
} catch (SQLException e) {
e.printStackTrace();
}
}
}jdbc.properties
driver=oracle.jdbc.driver.OracleDriver
url=jdbc:oracle:thin:@localhost:1521:SYSLOG
username=*****
password=*****
#定义初始连接数
initialSize=0
#定义最大连接数
maxActive=20
#定义最大空闲
maxIdle=20
#定义最小空闲
minIdle=1
#定义最长等待时间
maxWait=60000
属性详解
| 属性名 | 类型 | 描述 |
|---|---|---|
| name | String | (必选) Appender 的名称。 |
| ignoreExceptions | boolean | 默认为 true ,表示当输出事件时出现的异常将会被内部记录而忽略。 当设置为 false 时,则会将异常传播给调用者。当将该 Appender 包装成 FailoverAppender 时,必须设置为 false 。 |
| filter | Filter | 指定一个过滤器来决定是否将日志事件传递给 Appender 处理。可以指定为一个 CompositeFilter 来使用多个过滤器。 |
| bufferSize | int | 如果设置的整数值大于 0,Appender 将会缓冲日志事件,当缓冲区达到指定大小时 flush。 |
| connectionSource | ConnectionSource | (必选) 设置获取数据库连接的连接源。 |
| tableName | String | (必选) 设置写入日期事件的数据库表。 |
| columnConfigs | ColumnConfig[] | (必选) 通过多个Column元素来设置写入日志数据的数据列以及如何写入日志数据。 |
| columnMappings | ColumnMapping[] | (必选) 设置数据列映射列表。每一列必须指定一个列名,每一列都可以通过指定全限定类名来设置转换类型。如果配置的类型是 ReadOnlyStringMap / ThreadContextMap或ThreadContextStack赋值兼容的(assignment-compatib),那么该列将会分别使用 MDC 或 NDC (取决于数据库如何处理 Map 或 List 类型的值)来填充。如果配置的类型是 java.util.Date 类型赋值兼容的,那么日志时间戳将转换为配置的日期类型。如果配置的类型是 java.sql.Clob 或 java.sql.NClob 兼容的,那么格式化的事件将分别设置为 Clob 或 NClob(与传统的 ColumnConfig 插件类似)。如果指定了 literal 属性,那么其值将会被用于 INSERT 查询而不会转译。否则,指定的布局或模式(layout 或 pattern)将会转换为配置的类型,存储在该列中。 |
当配置了 JDBCAppender,必须指定一个 ConnectionSource 实现来获取 JDBC 连接。必须指定以下某个内嵌元素:
DataSource:使用 JNDI;
ConnectionFactory:(常用)指向提供 JDBC 连接的类方法对;
DriverManager:不使用连接池,这是一种快速但不推荐的脏方法;
PoolingDriver:使用 Apache Commons DBCP 提供连接池。
- DataSource 元素属性
| 属性名 | 类型 | 描述 |
|---|---|---|
| jndiName | String | (必选) 设置 javax.sql.DataSource 绑定的完整 JNDI 前缀,比如 java:/comp/env/jdbc/LoggingDatabase 。DataSource 必须支持连接池,否则,日志记录会很慢。 |
- ConnectionFactory 元素属性
| 属性名 | 类型 | 描述 |
|---|---|---|
| class | Class | (必选) 设置一个全限定类名,该类含有一个获取 JDBC 连接的静态工厂方法。 |
| method | Method | (必选) 设置获取 JDBC 连接的静态工厂方法名。该方法不能有参数,且其返回值必须得是 java.sql.Connection 或 DataSource 。如果该方法返回的是数据库连接,那么数据库连接必须是连接池提供的,不然日志记录就会很慢。如果该方法返回的是数据源,那么该数据源只需要获取一次,出于同样的原因,该数据源也需要支持连接池。 |
- DriverManager 元素属性
| 属性名 | 类型 | 描述 |
|---|---|---|
| connectionString | String | (必选) 设置基于特定驱动的 JDBC 连接字符串。 |
| userName | String | 数据库用户名。不能同时中指定 properties 属性和用户名或密码。 |
| password | String | 数据库密码。不能同时指定 properties 属性和用户名或密码。 |
| driverClassName | String | JDBC 驱动类名。某些老的 JDBC 驱动只能显式通过类名来加载。 |
| properties | Property[] | 属性列表。 不能同时指定 properties 属性和用户名或密码。 |
- PoolingDriver(Apache Commons DBCP) 元素属性
| 属性名 | 类型 | 描述 |
|---|---|---|
| DriverManager parameters | DriverManager parameters | 连接源从 DriverManager 连接源继承来所有参数。 |
| poolName | String | JDBC 连接池的名称。默认为 example。可以使用 JDBC 连接前缀 jdbc:apache:commons:dbcp:(Apache Commons DBCP) 后面跟上连接池的名称,例如: jdbc:apache:commons:dbcp:example。 |
| PoolableConnectionFactory | PoolableConnectionFactory | 定义一个 PoolableConnectionFactory。 |
- Column 元素属性
| 属性名 | 类型 | 描述 |
|---|---|---|
| name | String | (必选)数据库表的列名。 |
| pattern | String | 此属性可以通过使用 PatternLayout 模式在本列中插入一个或多个来自日志事件的值。 只需在此属性中指定任何合法模式。 必须指定这个属性或 literal 或 isEventTimestamp="true",但不能多于一个。 |
| literal | String | 使用该属性为该列插入一个文本值。该值将直接包含在 Insert SQL 语句中,不包含任何引号(这意味着如果你想将其作为字符串,你的值应该包含像这样的单引号:literal=”‘Literal String’”)。 这对于不支持自动生成主键值的数据库特别有用。 比如,如果你使用 Oracle,你可以指定 literal="NAME_OF_YOUR_SEQUENCE.NEXTVAL" 在主键列中插入一个唯一的 ID。 必须指定这个属性或 pattern 或 isEventTimestamp=”true”,但不能多于一个。 |
| parameter | String | 使用此属性在这一列里插入一个带有 ? 参数的表达式。该值将直接包含在 Insert SQL 语句中,不包含任何引号(这意味着如果你想将其作为字符串,你的值应该包含像这样的单引号:只能指定 literal 或 parameter 中的一个。 |
| isEventTimestamp | boolean | 使用此属性将事件时间戳插入到此列中,该列应该是一个 SQL 日期时间。该值将按照 java.sql.Types.TIMESTAMP 类型插入。必须指定这个属性或 literal 或 pattern,但不能多于一个。 |
| isUnicode | boolean | 除非指定了 pattern ,否则该属性将被忽略。 如果 true 或省略(默认false),该值将按 Unicode 插入(setNString 或 setNClob),否则,该值将会以非 Unicode 插入(setString 或 setClob)。 |
| isClob | boolean | 除非指定了 pattern ,否则该属性将被忽略。使用该属性表明该列是否用来存储 Character Large Objects(CLOBs)。如果设置为 true,该值将被插入为 CLOB(setClob 或 setNClob),如果设置为 false 或忽略(默认false),该值将被插入为 VARCHAR 或 NVARCHAR(setString 或 setNString)。 |
注:JDBCAppender 使用带有占位符的PreparedStatement 来插入 SQL 记录。
- ColumnMapping 元素属性
| 属性名 | 类型 | 描述 |
|---|---|---|
| name | String | (必选)数据库表的列名。 |
| pattern | String | 此属性可以通过使用 PatternLayout 模式在本列中插入一个或多个来自日志事件的值。 只需在此属性中指定任何合法模式。 必须指定这个属性或 literal 或 isEventTimestamp="true",但不能多于一个。 |
| literal | String | 使用该属性为该列插入一个文本值。该值将直接包含在 Insert SQL 语句中,不包含任何引号(这意味着如果你想将其作为字符串,你的值应该包含像这样的单引号:literal=”‘Literal String’”)。 这对于不支持自动生成主键值的数据库特别有用。 比如,如果你使用 Oracle,你可以指定 literal="NAME_OF_YOUR_SEQUENCE.NEXTVAL" 在主键列中插入一个唯一的 ID。 必须指定这个属性或 pattern 或 isEventTimestamp=”true”,但不能多于一个。 |
| layout | layout | 用来格式化 LogEvent 的 Layout。 |
| type | String | 转换类型名称,是一个全限定名。 |
<Configuration status="debug"> |
Layout
Appender 在将日志数据写入目标位置之前,一般会将日志数据通过 Layout 进行格式化。
- Layout 也可以通过特定的 Layout 插件名或 layout 元素(带有指定 Layout 插件名的 type 属性)来配置。
- Log4j 提供了多种不同的Layout来适用于多种形式的输出,如JSON、XML、HTML 和 Syslog (包括最新的 RFC 5424 版本).
PatternLayout 可以使用与C语言printf函数类似的转换模式来指定输出格式,PatternLayout 可以使用一些%开头的转换说明符( conversion specifier ),每个转换说明符包含一个可选的格式修饰符(format modifier)和一个转换字符(conversion character)来格式化日志事件的数据输出。
格式修饰符(format modifier)用于指定字段宽度、填充、左右对齐等。 “%-5p [%t]: %m%n”表明日志级别(%p)是向左对齐,宽度为5个字符,可能的日志输出内容为:
DEBUG [main]: Message 1 |
常用的转换说明符如下:
- %c{precision},%logger{precision}
logger的名称,precision可以是一个正整数、负整数、“1.”、“1.1..”、“.”等格式,用于指定输出的logger的名称的层级和详细程度。
| 转换模式 | 日志名字 | 结果 |
|---|---|---|
| %c{1} | org.apache.commons.Foo | Foo |
| %c{2} | org.apache.commons.Foo | commons.Foo |
| %c{10} | org.apache.commons.Foo | org.apache.commons.Foo |
| %c{-1} | org.apache.commons.Foo | apache.commons.Foo |
| %c{-2} | org.apache.commons.Foo | commons.Foo |
| %c{-10} | org.apache.commons.Foo | org.apache.commons.Foo |
| %c{1.} | org.apache.commons.Foo | o.a.c.Foo |
| %c{1.1..} | org.apache.commons.Foo | o.a…Foo |
| %c{.} | org.apache.commons.Foo | ….Foo |
%C{precision},%class{precision}
输出调用者的权限定类名,precision的规则与logger名称的用法相同。Log4j在输出类名时会检查堆栈信息,是耗时的操作,建议使用%c{precision}或%logger{precision}代替。%d{pattern},%date{pattern}
输出日志事件的时间,pattern经常包含若干对包含时间/日期格式(SimpleDateFormat)的花括号。
| 模式 | 范例 |
|---|---|
%d{DEFAULT} (默认) |
2012-11-02 14:34:02,123 |
| %d{DEFAULT_MICROS} | 2012-11-02 14:34:02,123456 |
| %d{DEFAULT_NANOS} | 2012-11-02 14:34:02,123456789 |
| %d{ISO8601} | 2012-11-02T14:34:02,781 |
| %d{ISO8601_BASIC} | 20121102T143402,781 |
| %d{ISO8601_OFFSET_DATE_TIME_HH} | 2012-11-02’T’14:34:02,781-07 |
| %d{ISO8601_OFFSET_DATE_TIME_HHMM} | 2012-11-02’T’14:34:02,781-0700 |
| %d{ISO8601_OFFSET_DATE_TIME_HHCMM} | 2012-11-02’T’14:34:02,781-07:00 |
| %d{ABSOLUTE} | 14:34:02,781 |
| %d{ABSOLUTE_MICROS} | 14:34:02,123456 |
| %d{ABSOLUTE_NANOS} | 14:34:02,123456789 |
| %d{DATE} | 02 Nov 2012 14:34:02,781 |
| %d{COMPACT} | 20121102143402700 |
| %d{UNIX} | 1351866842 |
| %d{UNIX_MILLIS} | 1351866842781 |
花括号里的内容也可以设置为包含特定时区Id( java.util.TimeZone.getTimeZone )的日期/时间模式的字符串
| 模式 | 范例 |
|---|---|
| %d{HH:mm:ss,SSS} | 14:34:02,123 |
| %d{HH:mm:ss,nnnn} | 14:34:02,1234 |
| %d{HH:mm:ss,nnnnnnnnn} | 14:34:02,123456789 |
| %d{dd MMM yyyy HH:mm:ss,SSS} | 02 Nov 2012 14:34:02,123 |
| %d{dd MMM yyyy HH:mm:ss,nnnn} | 02 Nov 2012 14:34:02,1234 |
| %d{dd MMM yyyy HH:mm:ss,nnnnnnnnn} | Nov 2012 14:34:02,123456789 |
| %d{HH:mm:ss}{GMT+0} | 18:34:02 |
| %d{yyyy-MM-dd HH:mm:ss.SSS} | 2020-4-20 23:30 |
- %L,%line
显示日志输出的代码所在的行数。Log4j在输出行号时会检查堆栈信息,是耗时的操作; - %m,%msg
输出应用中自定义的日志内容; - %M,%method
输出方法名。Log4j在输出行号时会检查堆栈信息,是耗时的操作; - %n
输出当前运行平台所用的换行符,一般放在末尾; - %p|level{level=label,level=label,…},%p|level{length=n},%p|level{lowerCase=true|false}
输出日志的级别。可以每个日志级别指定别名,如%level{WARN=W, DEBUG=D, ERROR=E, TRACE=T,INFO=I},%level{length=1}也可以实现同样的效果,如果length的值超过了日志级别的名称,那么使用正常的日志级别名称。level=label和length=n可以组合使用,如%level{ERROR=Error,length=2}为ERROR级别指定了别名,为其他日志级别限定了长度。此外,还可以指定级别的大小写; - %T,%tid,%threadId
输出日志的线程号,非常有必要; - %t,%tn,%thread,%threadName
输出日志的线程名称,类似于线程号作用相同,可选择其中一个; - %%
用于输出一个%。
Filter
log4j2走过滤器的逻辑后,会返回对应的过滤结果,以控制是否记录日志、怎样记录日志。过滤器的结果有:
- Accept:表示日志事件会被立即处理,不会调用其他 Filter;
- Deny:表示日志事件被立即忽略并不再经过其他过滤器;
- Neutral:表示日志事件将传递给其他Filter,如果没有其他Filter,则事件将会被处理。
注:log4j2的此机制与logback是一样的。
内置过滤器
| 过滤器 | 说明 | 是否常用 |
|---|---|---|
| StringMatchFilter | 如果格式化后(即:最终)的日志信息中包含\${指定的字符串},则onMatch,否则onMismatch。即:msg.contains(this.text) ? onMatch : onMismatch; |
是 |
| LevelRangeFilter | 若\${maxLevel} <= 日志级别 <= \${minLevel}, 则onMatch,否则onMismatch。如: 即为只记录日志info及warn级别的日志。 |
是 |
| RegexFilter | 如果日志信息匹配\${指定的正则表达式},则onMatch,否则onMismatch。注:可通过useRawMsg属性来控制这个日志信息是格式化处理后(即:最终)的日志信息,还是格式化处理前(即:代码中输入)的日志信息。 |
是 |
| ThresholdFilter | 若日志级别 >= \${指定的日志级别}, 则onMatch,否则onMismatch |
是 |
| LevelMatchFilter | 如果日志级别等于\${指定的日志级别},则onMatch,否则onMismatch |
是 |
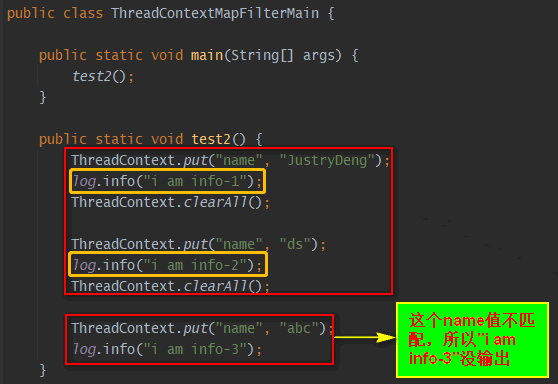
| ThreadContextMapFilter | 通过context(可以理解为一个Map)中对应的key-value值进行过滤。注:上下文默认是ThreadContext,也可以自定义使用ContextDataInjectorFactory配置ContextDataInjector来指定。” |
是 |
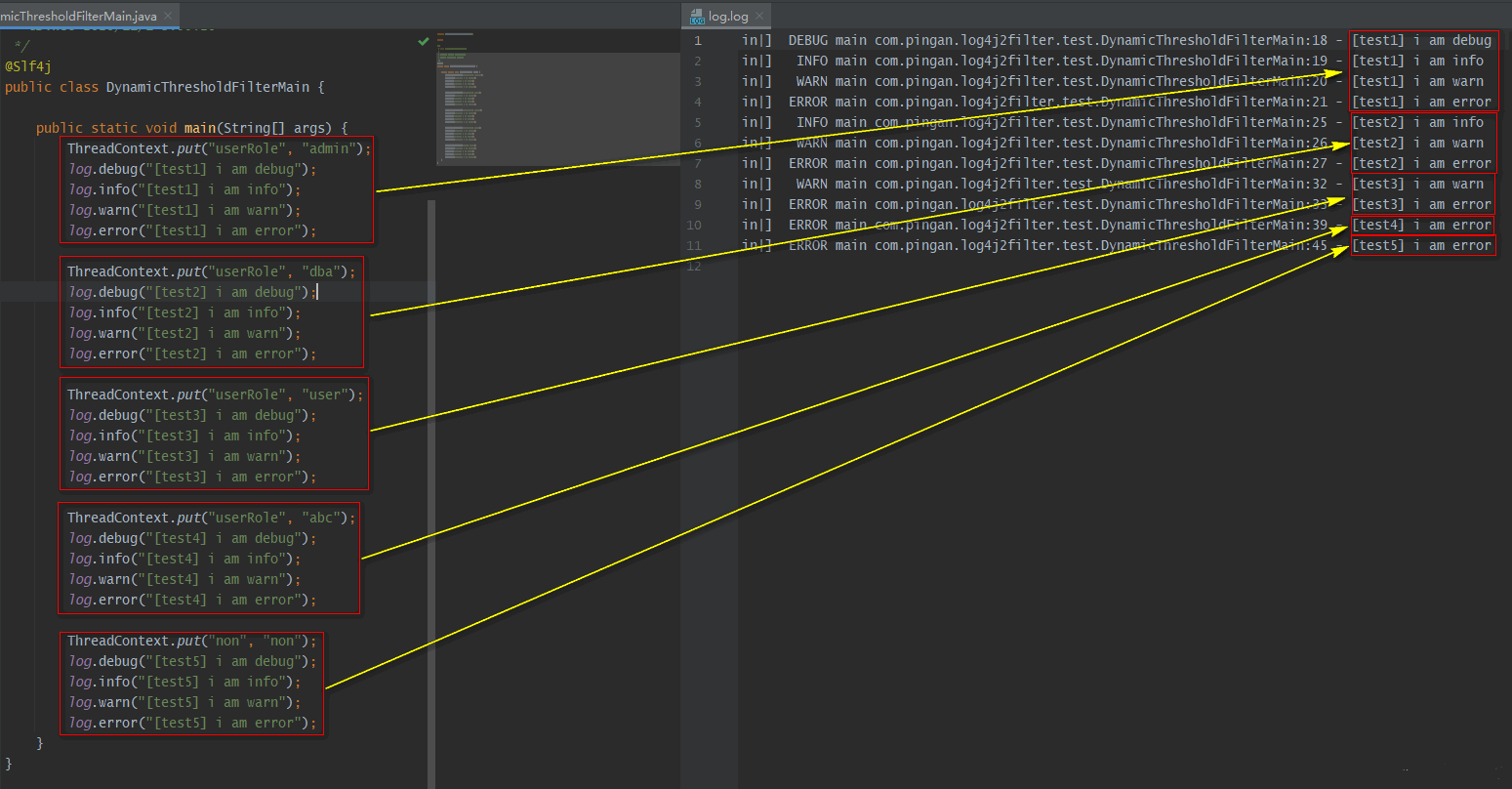
| DynamicThresholdFilter | 若上下文中包含指定的key,则触发DynamicThresholdFilter生效;若该key对应的value值等于任意一个我们指定的值,那么针对本条日志,可记录日志级别的约束下限调整为指定的级别。注:上下文默认是ThreadContext,也可以自定义使用ContextDataInjectorFactory配置ContextDataInjector来指定。 示例说明: <DynamicThresholdFilter key=""loginRole"" defaultThreshold=""ERROR"" onMatch=""ACCEPT"" onMismatch=""NEUTRAL""><KeyValuePair key=""admin"" value=""DEBUG""/><KeyValuePair key=""user"" value=""warn""/></DynamicThresholdFilter>配置,有以下情况:情况一:存在键loginRole,假设从上下文(可以理解为一个Map)中取出来的对应的值为user,那么此时,对于日志级别大于等于warn的日志,会走onMatch;其它的日志级别走onMismatch。情况二:存在键loginRole,假设从context(可以理解为一个Map)中取出来的对应的值为admin,那么此时,对于日志级别大于等于debug的日志,会走onMatch;其它的日志级别走onMismatch。情况三:【上下文(可以理解为一个Map)中,不存在键loginRole】或【存在键loginRole,但从日志上下文中取出来的值(假设)为abc, 没有对应的KeyValuePair配置】,那么此时<DynamicThresholdFilter key=""userRole"" defaultThreshold=""AAA"" onMatch=""BBB"" onMismatch=""CCC"">等价于<LevelMatchFilter level=""AAA"" onMatch=""BBB"" onMismatch=""CCC"">。 |
是 |
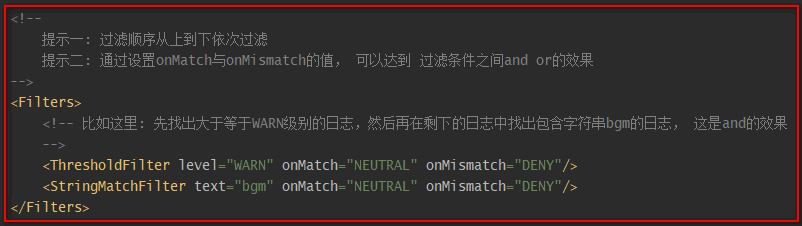
| CompositeFilter | 组合过滤器,即:按照xml配置中的配置,一个过滤器一个过滤器的走,如果在这过程中,任意一个过滤器ACCEPT或DENY了,那么就不会往后走了,直接返回对应的结果。 |
是 |
| TimeFilter | 如果记录日志时的当前时间落在每天指定的时间范围[start, end]内,则onMatch,否则onMismatch。如:<TimeFilter start=""05:00:00"" end=""05:30:00"" onMatch=""ACCEPT"" onMismatch=""DENY""/>。 |
否 |
| ScriptFilter | 是否匹配取决于指定的脚本返回值是否为true | 否 |
| DenyAllFilter | 此过滤器将导致删除所有日志事件 | 否 |
| BurstFilter | 对低于或等于\${指定日志级别}的日志,进行限流控制 |
否 |
| NoMarkerFilter | 如果从对应事件对象获取(LogEvent#getMarker)到的marker为null, 则onMatch,否则onMismatch | 否 |
| MarkerFilter | 如果从对应事件对象获取(LogEvent#getMarker)到的marker的name值为等于\${指定的值}, 则onMatch,否则onMismatch |
否 |
| MapFilter | MapFilter允许对MapMessage中的数据元素进行过滤。注:需要使用org.apache.logging.log4j.Logger进行记录,且记录org.apache.logging.log4j.message.MapMessage日志,才会生效。注:因为暂时不兼容Slf4j这里不多作说明 | 否 |
| StructuredDataFilter | StructuredDataFilter是一个MapFilter,它也允许过滤事件id、类型和消息。注:需要使用org.apache.logging.log4j.Logger进行记录,且记录org.apache.logging.log4j.core.filter.StructuredDataFilter日志,才会生效。注:因为暂时不兼容Slf4j这里不多作说明 | 否 |
作用范围
log4j2在处理日志时,各个Filter会组成过滤链,越靠前的Filter越先过滤,自然影响范围就越大。在log4j2的xml配置文件中,Filter可以配置在四个位置,由全局到局部依次是Context-wide、Logger和Appender、AppenderReference, 图示说明: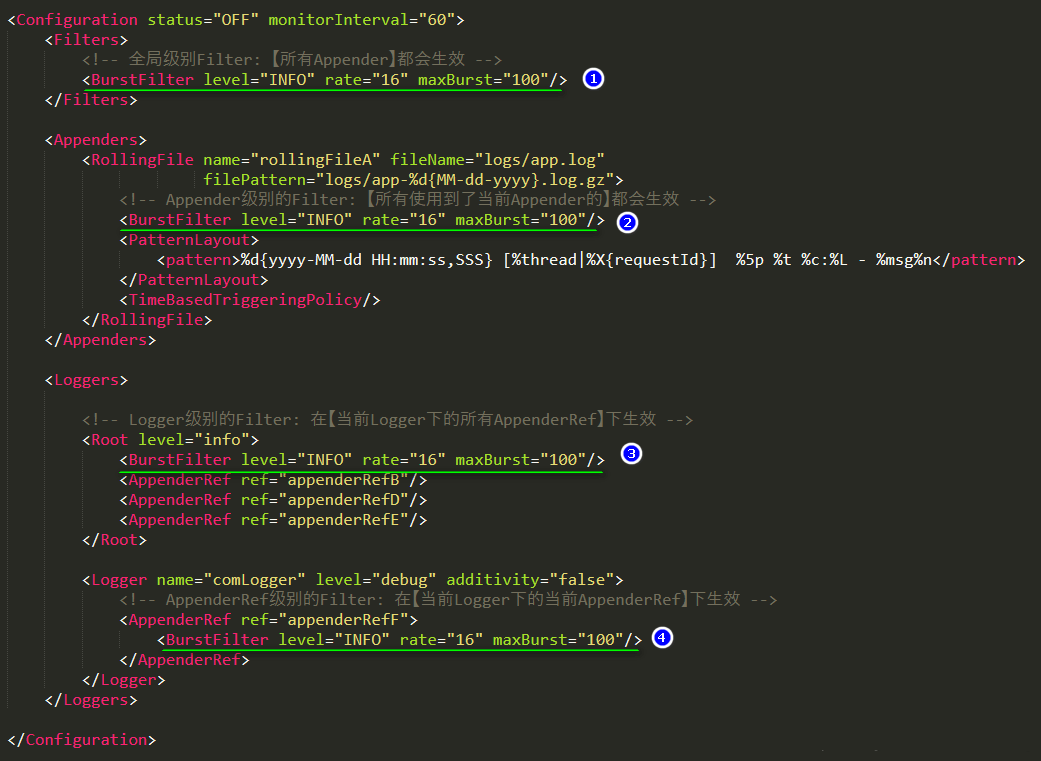
实例
- StringMatchFilter



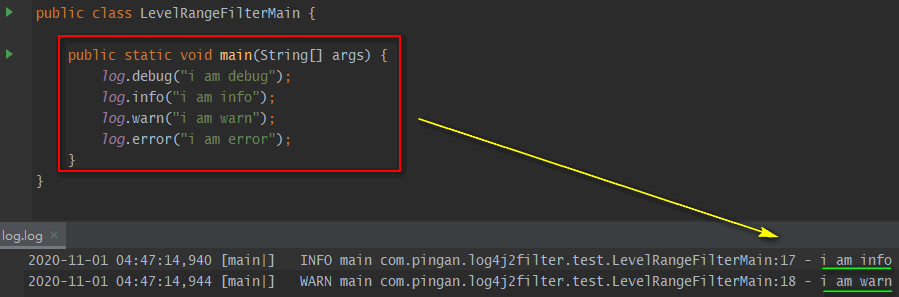
- LevelRangeFilter

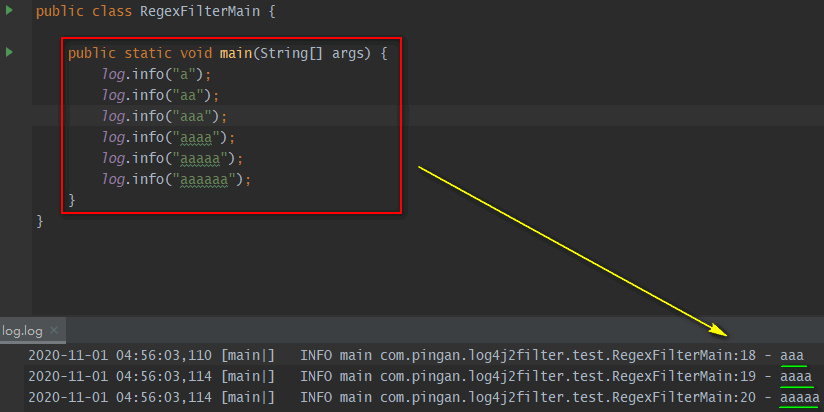
- RegexFilter

- ThresholdFilter

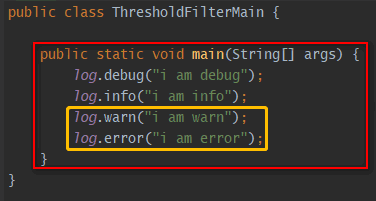
- LevelMatchFilter

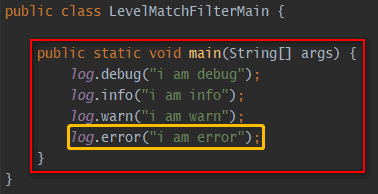
- ThreadContextMapFilter
示例一: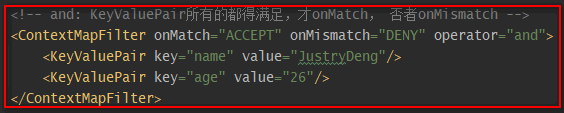
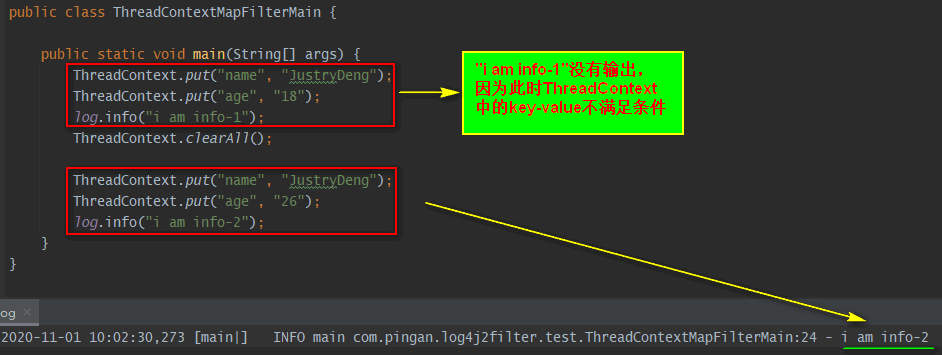
示例二: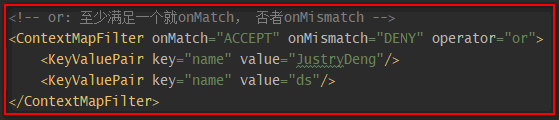
- DynamicThresholdFilter

- CompositeFilter

log4j2官方提供的过滤器已足够使用,
如需自定义过滤器,可以继承AbstractFilter,或者直接实现Filter。
Loggers
LoggerConfig
LoggerConfig 通过 Logger 元素进行配置。
<Logger name="druid.sql.Statement" level="debug" additivity="false"> |
Logger 元素可用属性如下:
| 属性 | 描述 |
|---|---|
| name | (必选)用于标识该 logger ; |
| level | 可选,用来设置日志级别。其值可以为TRACE、DEBUG、INFO、WARN、ERROR、ALL 或者OFF。如果没有指定该属性,则默认为 ERROR; |
| additivity | 可选的布尔值,用来设置相加性。如果没有指定该属性,则默认为 true。 |
LoggerConfig(包括 root LoggerConfig)可以通过属性来配置,这些属性将会添加到 ThreadContextMap 中的属性复本中。Appender、Filter、 Layout 等可以引用这些属性,就好像这些属性是 ThreadContextMap 中的属性一样。这些属性中的变量可以在解析(parse)配置或动态输出打印日志时计算(resolve)出来。
LoggerConfig 也可以通过一个或多个 AppenderRef 元素来配置,每个 Appender 的引用将会关联到特定的 LoggerConfig。如果一个 LoggerConfig 配置了多个 Appender,那么其中的每个 Appender 都会等价地处理日志事件。
root
每个配置都必须要有一个 root Logger,如果没有显式配置 root LoggerConfig,那么默认的 root LoggerConfig 的日志级别为 ERROR、Appender 为 Console 。root Logger 和其他 Logger 的不同主要在于以下两点:
- root Logger
没有 name 属性;- root Logger
不支持 additivity 属性,因为它没有 parent。
Additivity
某个 Logger 所允许的每条日志打印请求都会传递给其 LoggerConfig 中的所有 Appender,也会传递给该 LoggerConfig 的 parent LoggerConfig 中的 Appender,这种现象称为相加性(Additivity)。也就是说,Appender 会从 LoggerConfig 的继承中继承相加性。这种特性可以用来汇整某几个 logger 的输出,可以在声明 Logger 的配置文件中设置 additivity="false" 来禁用这种叠加继承。
- 如果一个 ConsoleAppender 添加到 root Logger中,那么所有允许的日志打印请求将至少输出到控制台,如果一个文件 Appender 添加到一个LoggerConfigC中,C和C的children允许的日志打印请求将会输出到文件和控制台。
- 如果 LoggerConfig C 中有一个 Logger L,那么 Logger L 的一条日志打印语句将输出到 L 关联的 LoggerConfig C 中的所有 Appender 以及该 LoggerConfig 的所有 ancestor。
- 然而,如果LoggerConfig C一个ancestor P的叠加标志设置为了false,那么,L 的输出将直接指向 C 中的所有 Appender 以及 C 的 ancestor 直到 P(包括 P),不会指向到 P 的所有 ancestor 中的 Appender。
Logger 的叠加标识默认为 true,表示叠加父级的 Appender。
日志级别的继承是指父级 LoggerConfig 的日志级别会被子级 LoggerConfig 所继承,而相加性是指子级Logger的日志时间会传递给父级Logger,两者刚好相反。
假如你想忽略除了 com.foo.Bar以外的所有TRACE日志,仅更改日志级别无法达到目的,解决办法是在配置文件中新建一个 logger 定义:
|
结果如下:
13:12:24.917 [main] TRACE com.foo.Bar - entry |
上面的配置记录了 com.foo.Bar 中的所有级别的日志事件,但其他所有组件的日志事件中只有 ERROR 级别的才会被记录。
如果我们为 com.foo.Bar 的 logger 配置了 Appender,如下所示:
|
结果如下:
13:25:55.391 [main] TRACE com.foo.Bar - entry |
com.foo.Bar 类中的 TRACE 级别及以上的日志竟然输出了两遍!这是由于名为 com.foo.Bar 的 logger 会将其打印事件传递给其 parent logger(这里为 Root ),在 Root logger 中再次执行了打印操作。
而案例 2 中的没有重复打印是由于名为 com.foo.Bar 的 logger 没有设置 Appender,它仅负责记录的打印事件,然后将其传递给了 Root logger,所以仅 Root logger 有打印操作。
在配置文件中设置 additivity="false" 来禁用这种叠加继承。
|
可以发现日志不会重复打印了:
13:46:27.869 [main] TRACE com.foo.Bar - entry |
属性替换
Log4j 2 支持使用特定符号来引用其他地方定义的属性。某些属性在翻译配置文件时计算(resolve)出来,某些属性传递到组件(component,比如 Logger 、Appender 等元素)中在运行时求值(evaluate)。Log4j 使用 Apache Commons Lang 的 StrSubstitutor 和 StrLookup 类来实现这一功能。与 Ant 或 Maven 相似的方式,允许使用 ${name} 形式的变量来计算配置中声明(通过 Property 元素)的属性。例如,下面的例子演示了如何声明和使用 RollingFile Appender 所用的日志输出文件名属性。
|
Log4j 也支持 \${prefix:name} 格式的语法,其中 prefix 标识告诉 Log4j 该变量应该在特定的上下文中求值(evaluate)。Log4j 内置的上下文如下:
| 前缀 | 上下文 |
|---|---|
| bundle | Resource bundle 。格式为${bundle:BundleName:BundleKey} 。其中,bundle name 遵循包名转换,例如,${bundle:com.domain.Messages:MyKey} 。 |
| ctx | Thread Context Map (MDC) |
| date | 使用特定的格式插入当前日期和/或时间 |
| env | 系统环境变量。格式为${env:ENV_NAME}和${env:ENV_NAME:-default_value} |
| jndi | 默认 JNDI Context 中设置的值 |
| jvmrunargs | 通过 JMX 访问的 JVM 输出参数,但不是主参数。参考 RuntimeMXBean.getInputArguments() 。 Android 上不可用。 |
| log4j | Log4j 的配置属性。表达式${log4j:configLocation}和${log4j:configParentLocation} 分别额提供log4j 配置文件的绝对路径和其父文件夹。 |
| main | 通过MapLookup.setMainArguments(String[]) 设置的一个值。 |
| map | MapMessage 中的一个值。 |
| sd | StructuredDataMessage 中的一个值。id 键将返回没有企业号(enterprise number)的 StructuredDataId 名。type 键将返回消息类型。其他键将获取 Map 中独立的元素。 |
| sys | 系统属性。格式为${sys:some.property}和${sys:some.property:-default_value} |
可以在配置文件中声明一个默认的属性映射。如果一个值在特定查找中无法定位到,那么将会使用默认属性映射中的值。默认属性映射预填充了一个表示当前系统主机名和 IP 的 hostName 属性 ,以及一个表示当前日志上下文的名为 contextName 属性。
当一个变量引用的开头为多个 $ 的字符时,StrLookup 将会去除前面的 $ 字符。在前面的例子中,Routes 元素能够在运行时计算(resolve)出 $${sd:type} 变量应用中的变量 sd:type 。该变量的前缀为两个 $ 字符,配置文件第一次处理时会去掉第一个 $ 字符,Routes 元素在运行时能够求出声明为 ${sd:type} 的变量,就会检查事件的 StructuredDataMessage ,如果存在,则其 type 属性将用作 routing key 。并不是所有的元素都可以在运行时计算(resolve)变量。
如果在前缀关联的 Lookup 中没有找到对应的键值,那么将会使用配置文件里属性声明中的键值。如果没有找到值,则将变量声明作为值返回。配置文件中的默认值可以这样声明:
|
注:在处理配置文件时,并不会对 RollingFile Appender 声明中的变量求值。这是因为整个 RollingFile 元素的解析会推迟到出现匹配时。
XInclude
XML 配置文件通过 XInclude 来引用其他文件。下面演示了 log4j2.xml 文件引用了其他两个文件。
- log4j2.xml 文件内容如下:
|
- log4j-xinclude-appenders.xml 文件内容如下:
|
- log4j-xinclude-loggers.xml 文件内容如下:
|
后述
Log4j2在用于Java EE Web应用时有一些额外事项需要注意。要确保日志资源在容器关闭或 Web 应用取消部署时能恰当地清理。为了做到这一点,需要在 Web 应用中添加 log4j-web 的依赖,可以从 Maven 仓库中找到该依赖。
Log4j 2 只能运行在支持 Servlet 3.0 及以上版本的Web应用中,它可以在应用部署时和关闭时随之自动启动和关闭。
注:有些容器会忽略不含 TLD 文件的 jar 文件